
- On writing well: Through the Eyes of Birds and Frogs : This article is a very interesting and helpful article about writing especially for academic papers and review articles.
- “Birds fly high in the air and survey broad vistas of mathematics out to the far horizon. They delight in concepts that unify our thinking. “
- “Frogs live in the mud below and see only the flowers that grow nearby. They delight in the details of particular objects.”
- “That the aim of our writing, whatever we might be writing, is to familiarise the strange and to mystify the familiar. “
- “Start writing with one simple fact that readers must know. Then add more by broadening this first point. The third adds to the second and broadens the reader’s set of facts and connections. Finally we achieve a new state of wisdom.”
- On On Offline Reinforcement Learning: @NandoDF: Offline Reinforcement Learning frees us to think about bigger problems than we have before. @JohnCLangford: Offline reinforcement learning might be the key to reinforcement learning.
- NIPS 2020 Offline Reinforcement Learning Workshop
- Statisticians need to learn such kind of reward driven framework using offline observed data. It’s a big change which makes us think more.
- Reinforcement Learning from Batch Data and Simulation
- NIPS 2020 Interesting Talks:
. . . the objective of statistical methods is the reduction of data. A quantity of data. . . is to be replaced by relatively few quantities which shall adequately represent. . . the
relevant information contained in the original data.Since the number of independent facts supplied in the data is usually far greater than the number of facts sought, much of the information supplied by an actual sample is irrelevant. It is the object of the statistical process employed in the reduction of data to exclude this irrelevant information, and to isolate the whole of the relevant information contained in the data.
—Fisher’s 1922 article “On the mathematical foundations of theoretical statistics”
Sufficiency is the concept to keep relevant information for the estimation of the target parameter. Since the raw data is of course sufficient, we will look for minimal (i.e. maximal reduction) and sufficient statistic. A minimal sufficient statistic may still contain some redundancy. In other words, there may be more than one way to estimate the parameter. Essentially, completeness says the only way to estimate 0 is with 0. If T is not complete, then it somehow can be used to estimate the same quantity two different ways.
Note that a further reduction of complete statistic is also complete. Hence the key point of completeness is that it indicates a reduction of the data to the point where there can be at most one unbiased estimator of any 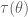
![E_{\theta}g_j(T)=\tau(\theta), j=1,2\Rightarrow E_{\theta}[g_1(T)-g_2(T)]=0,\forall\theta\Rightarrow g_1=g_2](https://s0.wp.com/latex.php?latex=E_%7B%5Ctheta%7Dg_j%28T%29%3D%5Ctau%28%5Ctheta%29%2C+j%3D1%2C2%5CRightarrow+E_%7B%5Ctheta%7D%5Bg_1%28T%29-g_2%28T%29%5D%3D0%2C%5Cforall%5Ctheta%5CRightarrow+g_1%3Dg_2&bg=ffffff&fg=545454&s=0&c=20201002)
Thus with the reduction keeping sufficiency, once it reaches completeness, we know that this sufficient and complete statistic is minimal sufficient if there exists one.
Here is a very nice geometric interpretation of completeness: https://stats.stackexchange.com/q/285503
- A nice blog on CS including learnings: https://blog.acolyer.org/ called “the morning paper”: an interesting/influential/important paper from the world of CS every weekday morning, as selected by Adrian Colyer. I hope there is a similar blog on Statistics, reviewing and recommending an interesting/influential/important paper from the world of Statistics.
- A wonderful summary of Mathematical Tricks Commonly Used in Machine Learning and Statistics with examples
- I just realized that when I teach ridge regression I should have used A Useful Matrix Inverse Equality for Ridge Regression
- GANs should be gained much attention in the stats community: Understanding Generative Adversarial Networks. This is a nice post about GANs based on “probably the highest-quality general overview available nowadays: Ian Goodfellow’s tutorial on arXiv, which he then presented in some form at NIPS 2016. “
- R or Python? Why not both? Using Anaconda Python within R with {reticulate}
- “A heatmap is basically a table that has colors in place of numbers. Colors correspond to the level of the measurement.”
You can install the StatRep package by downloading statrep.zip from support.sas.com/StatRepPackage, which contains:
- doc/statrepmanual.pdf – The StatRep User’s Guide (this manual)
- doc/quickstart.tex – A template and tutorial sample LATEX file
- sas/statrep_macros.sas – The StatRep SAS macros
- sas/statrep_tagset.sas – The StatRep SAS tagset for LaTeX tabular output
- statrep.ins – The LATEX package installer file
- statrep.dtx – The LATEX package itself
Unzip the file statrep.zip to a temporary directory and perform the following steps:
- Step 1: Install the StatRep SAS Macros: Copy the file statrep_macros.sas to a local directory. If you have a folder where you keep your personal set of macros, copy the file there. Otherwise, create a directory such as C:\mymacros and copy the file into that directory.
- Step 2: Install the StatRep LaTeX Package: These instructions show how to install the StatRep package in your LATEX distribution for your personal use.
- a. For MikTEX users: If you do not have a directory for your own packages, choose a directory name to contain your packages (for example, C:\localtexmf). In the following instructions, this directory is referred to as the “root directory”.
- b. Create the additional subdirectories under the above root directory: tex/latex/statrep. Your directory tree will have the following structure: root directory/tex/latex/statrep.
- c. Copy the files statrep.dtx, statrep.ins, statrepmanual.pdf, and statrepmanual.tex to the statrep subdirectory.
- d. In the command prompt, cd to the statrep directory and enter the following command: pdftex statrep.insThe command creates several files, one of which is the configuration file, statrep.cfg.
- Step 3: Tell the StatRep Package the Location of the StatRep SAS Macros. Edit the statrep.cfg file that was generated in Step 2d so that the macro \SRmacropath contains the correct location of the macro file from step 1. For example, if you copied the statrep_macros.sas file to a directory named C:\mymacros, then you de- fine macro \SRmacropath as follows: \def\SRmacropath{C:/mymacros/statrep_macros.sas} Use the forward slash as the directory name delimiter instead of the backslash, which is a special character in LaTeX.
You can now test and experiment with the package. Create a working directory, and copy the file quickstart.tex into it. To generate the quick-start document:
- Compile the document with pdfLATEX. You can use a LATEX-aware editor such as TEXworks, or use the command-line command pdflatex. This step generates the SAS program that is needed to produce the results.
- Execute the SAS program quickstart_SR.sas, which was automatically created in the preceding step. This step generates the SAS results that are requested in the quick-start document.
- Recompile the document with pdfLATEX. This step compiles the quick-start document to PDF, this time including the SAS results that were generated in the preceding step. In some cases listing outputs may not be framed properly after this step. If your listing outputs are not framed properly, repeat this step so that LaTeX can remeasure the listing outputs.
Please refer to the following file for detailed information:
Click to access statrepmanual.pdf
Yesterday I learned something interesting from a talk given by Professor Bikas K Sinha. The following is an excerpt from the reference [1], which exactly shows the interesting point of the problem.
“A population consisting of an unknown number of distinct species is searched by selecting one member at a time. No a priori information is available concerning the probability that an object selected from this population will represent a particular species. Based on the information available after an n-stage search it is desired to predict the conditional probability that the next selection will represent a species not represented in the n-stage sample.”
Searcher: “I am contemplating extending my initial search an additional m stages, and will so do if the expected number of individuals I will select in the second search who are new species is large. What do you recommend?”
Statistician: “Make one more search and then I will tell you.”
Refer to the Annals of Statistics paper:
[1] Starr, Norman. “Linear estimation of the probability of discovering a new species.” The Annals of Statistics (1979): 644-652.
Recently I was referred to a nice article talking about the relationship between Statistics and data science. Here is my feedback to share with you:
- First of all, Statistics is a science dealing with data, including five main components, data collection (design of experiment, sampling), data preparation (storage, reading, organization, cleaning), exploratory data analysis (numerical summarization, visualization), statistical inference (frequentist and Bayesian) and communication (interpretation).
- It’s statistician’s mistake putting extremely unequal weights on the development of the five components in the past 50 years, mostly focusing on the fourth component.
- Fortunately, the first component is now showing resurgence under the massive data situation. How to sample the “influential” data points from massive samples is a big and important research topic.
- People outside of traditional statistics community have been picking up the second and third components, like adopting the two undeveloped statistics children. And the adoptive parents are saying that the two children are not statistics, and instead they call them data science.
- But Statistics is really about all of the five equally important components.
- And our Statistician’s goal is to get the two children back to our statistics community. We are all Statistician!
I graduated from MSU this summer and moved to Indianapolis as an assistant professor of Statistics at IUPUI. This is my first official job in life. Welcome to my Homepage: math.iupui.edu/~hlwang !
- Deep Learning Master Class
- Advances in Variational Inference
- Numerical Optimization: Understanding L-BFGS
- An exact mapping between the Variational Renormalization Group and Deep Learning
- New ASA Guidelines for Undergraduate Statistics Programs
- 奇异值分解(We Recommend a Singular Value Decomposition)
- 如何简单形象又有趣地讲解神经网络是什么?
- Academic vs. Industry Careers
- Hadley Wickham: Impact the world by being useful
- Statisticians in World War II: They also served
- A Brief Overview of Deep Learning
- Advice for applying Machine Learning
- Deep Learning Tutorial
- Gibbs Sampling in Haskell
- How-to go parallel in R – basics + tips
The first colloquium speaker at this semester, professor Wei Zheng from IUPUI, will give a talk on “Universally optimal designs for two interference models“. In this data explosive age, people are easy to get big data set, which renders people difficult to make inferences from such massive data. Since people usually think that with more data, they have more chance to get more useful information from them, lots of researchers are struggling to achieve methodological advancements under this setup. This is a very challenging research area and of course very important, which in my opinion needs the resurgence of mathematical statistics by borrowing great ideas from various mathematical fields. However, another great and classical statistical research area should come back again to help statistical inference procedures from the beginning stage of data analysis, collecting data by design of experiments so that we can control the data quality, usefulness and size. Thus it’s necessary for us to know what is optimal design of experiments. Here is an introduction to this interesting topic.
In statistics, we have to organize an experiment in order to gain some information about an object of interest. Fragments of this information can be obtained by making observations within some elementary experiments called trials. The set of all trials which can be incorporated in a prepared experiment will be denoted by 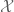

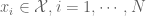
We shall restrict our attention to the parametric situation in the case of a regression model, the mean response function is then parameterized as
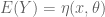
specifying for a particular 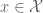

A design is specified by an initially arbitrary measure 

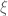
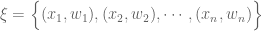
where the 



where 

Now we have to propose the statistical criteria for the optimum. It is known that the least squares estimator minimizes the variance of mean-unbiased estimators (under the conditions of the Gauss–Markov theorem). In the estimation theory for statistical models with one real parameter, the reciprocal of the variance of an (“efficient”) estimator is called the “Fisher information” for that estimator. Because of this reciprocity, minimizing the variance corresponds to maximizing the information. When the statistical model has several parameters, however, the mean of the parameter-estimator is a vector and its variance is a matrix. The inverse matrix of the variance-matrix is called the “information matrix”. Because the variance of the estimator of a parameter vector is a matrix, the problem of “minimizing the variance” is complicated. Using statistical theory, statisticians compress the information-matrix using real-valued summary statistics; being real-valued functions, these “information criteria” can be maximized. The traditional optimality-criteria are invariants of the information matrix; algebraically, the traditional optimality-criteria are functionals of the eigenvalues of the information matrix.
- A-optimality (“average” or trace)
- One criterion is A-optimality, which seeks to minimize the trace of the inverse of the information matrix. This criterion results in minimizing the average variance of the estimates of the regression coefficients.
- D-optimality (determinant)
- A popular criterion is D-optimality, which seeks to maximize the determinant of the information matrix of the design. This criterion results in maximizing the differential Shannon information content of the parameter estimates.
- E-optimality (eigenvalue)
- Another design is E-optimality, which maximizes the minimum eigenvalue of the information matrix.
- T-optimality
- This criterion maximizes the trace of the information matrix.
Other optimality-criteria are concerned with the variance of predictions:
- G-optimality
- A popular criterion is G-optimality, which seeks to minimize the maximum entry in the diagonal of the hat matrix. This has the effect of minimizing the maximum variance of the predicted values.
- I-optimality (integrated)
- A second criterion on prediction variance is I-optimality, which seeks to minimize the average prediction variance over the design space.
- V-optimality (variance)
- A third criterion on prediction variance is V-optimality, which seeks to minimize the average prediction variance over a set of m specific points.
Now back to our example, because the asymptotic covariance matrix associated with the LSE of 

and G-optimality seeks to minimize 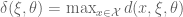
A central result in the theory of optimal design, the General Equivalence Theorem, asserts that the design 

the number of parameters.
Now the optimal design for an interference model, professor Wei Zheng will talk about, considers the following model in the block designs with neighbor effects:
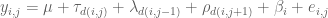
where 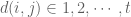

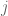

is the general mean;
is the direct effect of treatment
;
and
are respectively the left and right neighbor effects; that’s the interference effect of the treatment assigned to, respectively, the left and right neighbor plots
and
.
is the effect of the
is the random error,
.
We seed the optimal design among designs 



I am not going into the details of the derivation of the optimal design for the above interference model. I just sketch the outline here. First of all we can write down the information matrix for the direct treatment effect 


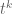

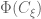
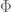
for any permutation matrix
;
is nondecreasing in the scalar
.
A measure 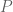
I am graduating as a fifth year PhD student and I really agree with Professor David Karger from MIT about the qualities characterizing a great PhD student, especially about the point on “discipline and productivity”. Professor Karger also distinguished the difference between a successful PhD for industry and a successful PhD for academic. Here I just cite the whole article to share with you as well as to keep these principles in my own mind:
As a CS prof at MIT, I have had the privilege of working with some of the very best PhD students anywhere. But even here there are some PhDs that clearly stand out as *great*. I’m going to give two answers, depending on your interpretation of “great”.
For my first answer I’d select four indispensable qualities:
0. intelligence
1. curiosity
2. creativity
3. discipline and productivity
(interestingly, I’d say the same four qualities characterize great artists).
In the “nice to have but not essential” category, I would add
4. ability to teach/communicate with an audience
5. ability to communicate with peers
The primary purpose of PhD work is to advance human knowledge. Since you’re working at the edge of what we know, the material you’re working with is hard—you have to be smart enough to master it (intelligence). This is what qualifying exams are about. But you only need to be smart *enough*—I’ve met a few spectacularly brilliant PhD students, and plenty of others who were just smart enough. This didn’t really make a difference in the quality of their PhDs (though it does effect their choice of area—more of the truly brilliant go into the theoretical areas).
But intelligence is just a starting point. The first thing you actually have to *do* to advance human knowledge is ask questions about why things are the way they are and how they could be made better (curiosity). PhD students spend lots of time asking questions to which they don’t know the answer, so you’d better really enjoy this. Obviously, after you ask the questions you have to come up with the answers. And you have to be able to think in new directions to answer those questions (creativity). For if you can answer those questions using tried and true techniques, then they really aren’t research questions—they’re just things we already know for which we just haven’t gotten around to filling in the detail.
These two qualities are critical for a great PhD, but also lead to one of the most common failure modes: students who love asking questions and thinking about cool ways to answer them, but never actually *do* the work necessary to try out the answer. Instead, they flutter off to the next cool idea. So this is where discipline comes in: you need to be willing to bang your head against the wall for months (theoretician) or spend months hacking code (practitioner), in order to flesh out your creative idea and validate it. You need a long-term view that reminds you why you are doing this even when the fun parts (brainstorming and curiosity-satisfying) aren’t happening.
Communication skills are really valuable but sometimes dispensable. Your work can have a lot more impact if you are able to spread it to others who can incorporate it in their work. And many times you can achieve more by collaborating with others who bring different skills and insights to a problem. On the other hand, some of the greatest work (especially theoretical work) has been done by lone figures locked in their offices who publish obscure hard to read papers; when that work is great enough, it eventually spreads into the community even if the originator isn’t trying to make it do so.
My second answer is more cynical. If you think about it, someone coming to do a PhD is entering an environment filled with people who excel at items 0-5 in my list. And most of those items are talents that faculty can continue to exercise as faculty, because really curiosity, creativity, and communication don’t take that much time to do well. The one place where faculty really need help is on productivity: they’re trying to advance a huge number of projects simultaneously and really don’t have the cycles to carry out the necessary work. So another way to characterize what makes a great PhD student is
0. intelligence
1. discipline and productivity
If you are off the scale in your productivity (producing code, running interviews, or working at a lab bench) and smart enough to understand the work you get asked to do, then you can be the extra pair of productive hands that the faculty member desperately needs. Your advisor can generate questions and creative ways to answer them, and you can execute. After a few years of this, they’ll thank you with a PhD.
If all you want is the PhD, this second approach is a fine one. But you should recognize that in this case that advisor is *not* going to write a recommendation letter that will get you a faculty position (though they’ll be happy to praise you to Google). There’s only 1 way to be a successful *faculty member*, and that’s my first answer above.
Update: Here is another article from Professors Mark Dredze (Johns Hopkins University) and Hanna M. Wallach (University of Massachusetts Amherst).

Recent Comments