
You are currently browsing the monthly archive for January 2019.
. . . the objective of statistical methods is the reduction of data. A quantity of data. . . is to be replaced by relatively few quantities which shall adequately represent. . . the
relevant information contained in the original data.Since the number of independent facts supplied in the data is usually far greater than the number of facts sought, much of the information supplied by an actual sample is irrelevant. It is the object of the statistical process employed in the reduction of data to exclude this irrelevant information, and to isolate the whole of the relevant information contained in the data.
—Fisher’s 1922 article “On the mathematical foundations of theoretical statistics”
Sufficiency is the concept to keep relevant information for the estimation of the target parameter. Since the raw data is of course sufficient, we will look for minimal (i.e. maximal reduction) and sufficient statistic. A minimal sufficient statistic may still contain some redundancy. In other words, there may be more than one way to estimate the parameter. Essentially, completeness says the only way to estimate 0 is with 0. If T is not complete, then it somehow can be used to estimate the same quantity two different ways.
Note that a further reduction of complete statistic is also complete. Hence the key point of completeness is that it indicates a reduction of the data to the point where there can be at most one unbiased estimator of any 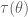
![E_{\theta}g_j(T)=\tau(\theta), j=1,2\Rightarrow E_{\theta}[g_1(T)-g_2(T)]=0,\forall\theta\Rightarrow g_1=g_2](https://s0.wp.com/latex.php?latex=E_%7B%5Ctheta%7Dg_j%28T%29%3D%5Ctau%28%5Ctheta%29%2C+j%3D1%2C2%5CRightarrow+E_%7B%5Ctheta%7D%5Bg_1%28T%29-g_2%28T%29%5D%3D0%2C%5Cforall%5Ctheta%5CRightarrow+g_1%3Dg_2&bg=ffffff&fg=545454&s=0&c=20201002)
Thus with the reduction keeping sufficiency, once it reaches completeness, we know that this sufficient and complete statistic is minimal sufficient if there exists one.
Here is a very nice geometric interpretation of completeness: https://stats.stackexchange.com/q/285503
- A nice blog on CS including learnings: https://blog.acolyer.org/ called “the morning paper”: an interesting/influential/important paper from the world of CS every weekday morning, as selected by Adrian Colyer. I hope there is a similar blog on Statistics, reviewing and recommending an interesting/influential/important paper from the world of Statistics.
- A wonderful summary of Mathematical Tricks Commonly Used in Machine Learning and Statistics with examples
- I just realized that when I teach ridge regression I should have used A Useful Matrix Inverse Equality for Ridge Regression
- GANs should be gained much attention in the stats community: Understanding Generative Adversarial Networks. This is a nice post about GANs based on “probably the highest-quality general overview available nowadays: Ian Goodfellow’s tutorial on arXiv, which he then presented in some form at NIPS 2016. “
- R or Python? Why not both? Using Anaconda Python within R with {reticulate}
- “A heatmap is basically a table that has colors in place of numbers. Colors correspond to the level of the measurement.”

Recent Comments