
You are currently browsing the monthly archive for December 2014.
I am graduating as a fifth year PhD student and I really agree with Professor David Karger from MIT about the qualities characterizing a great PhD student, especially about the point on “discipline and productivity”. Professor Karger also distinguished the difference between a successful PhD for industry and a successful PhD for academic. Here I just cite the whole article to share with you as well as to keep these principles in my own mind:
As a CS prof at MIT, I have had the privilege of working with some of the very best PhD students anywhere. But even here there are some PhDs that clearly stand out as *great*. I’m going to give two answers, depending on your interpretation of “great”.
For my first answer I’d select four indispensable qualities:
0. intelligence
1. curiosity
2. creativity
3. discipline and productivity
(interestingly, I’d say the same four qualities characterize great artists).
In the “nice to have but not essential” category, I would add
4. ability to teach/communicate with an audience
5. ability to communicate with peers
The primary purpose of PhD work is to advance human knowledge. Since you’re working at the edge of what we know, the material you’re working with is hard—you have to be smart enough to master it (intelligence). This is what qualifying exams are about. But you only need to be smart *enough*—I’ve met a few spectacularly brilliant PhD students, and plenty of others who were just smart enough. This didn’t really make a difference in the quality of their PhDs (though it does effect their choice of area—more of the truly brilliant go into the theoretical areas).
But intelligence is just a starting point. The first thing you actually have to *do* to advance human knowledge is ask questions about why things are the way they are and how they could be made better (curiosity). PhD students spend lots of time asking questions to which they don’t know the answer, so you’d better really enjoy this. Obviously, after you ask the questions you have to come up with the answers. And you have to be able to think in new directions to answer those questions (creativity). For if you can answer those questions using tried and true techniques, then they really aren’t research questions—they’re just things we already know for which we just haven’t gotten around to filling in the detail.
These two qualities are critical for a great PhD, but also lead to one of the most common failure modes: students who love asking questions and thinking about cool ways to answer them, but never actually *do* the work necessary to try out the answer. Instead, they flutter off to the next cool idea. So this is where discipline comes in: you need to be willing to bang your head against the wall for months (theoretician) or spend months hacking code (practitioner), in order to flesh out your creative idea and validate it. You need a long-term view that reminds you why you are doing this even when the fun parts (brainstorming and curiosity-satisfying) aren’t happening.
Communication skills are really valuable but sometimes dispensable. Your work can have a lot more impact if you are able to spread it to others who can incorporate it in their work. And many times you can achieve more by collaborating with others who bring different skills and insights to a problem. On the other hand, some of the greatest work (especially theoretical work) has been done by lone figures locked in their offices who publish obscure hard to read papers; when that work is great enough, it eventually spreads into the community even if the originator isn’t trying to make it do so.
My second answer is more cynical. If you think about it, someone coming to do a PhD is entering an environment filled with people who excel at items 0-5 in my list. And most of those items are talents that faculty can continue to exercise as faculty, because really curiosity, creativity, and communication don’t take that much time to do well. The one place where faculty really need help is on productivity: they’re trying to advance a huge number of projects simultaneously and really don’t have the cycles to carry out the necessary work. So another way to characterize what makes a great PhD student is
0. intelligence
1. discipline and productivity
If you are off the scale in your productivity (producing code, running interviews, or working at a lab bench) and smart enough to understand the work you get asked to do, then you can be the extra pair of productive hands that the faculty member desperately needs. Your advisor can generate questions and creative ways to answer them, and you can execute. After a few years of this, they’ll thank you with a PhD.
If all you want is the PhD, this second approach is a fine one. But you should recognize that in this case that advisor is *not* going to write a recommendation letter that will get you a faculty position (though they’ll be happy to praise you to Google). There’s only 1 way to be a successful *faculty member*, and that’s my first answer above.
Update: Here is another article from Professors Mark Dredze (Johns Hopkins University) and Hanna M. Wallach (University of Massachusetts Amherst).
There has been a Machine Learning (ML) reading list of books in hacker news for a while, where Professor Michael I. Jordan recommend some books to start on ML for people who are going to devote many decades of their lives to the field, and who want to get to the research frontier fairly quickly. Recently he articulated the relationship between CS and Stats amazingly well in his recent reddit AMA, in which he also added some books that dig still further into foundational topics. I just list them here for people’s convenience and my own reference.
- Frequentist Statistics
- Casella, G. and Berger, R.L. (2001). “Statistical Inference” Duxbury Press.—Intermediate-level statistics book.
- Ferguson, T. (1996). “A Course in Large Sample Theory” Chapman & Hall/CRC.—For a slightly more advanced book that’s quite clear on mathematical techniques.
- Lehmann, E. (2004). “Elements of Large-Sample Theory” Springer.—About asymptotics which is a good starting place.
- Vaart, A.W. van der (1998). “Asymptotic Statistics” Cambridge.—A book that shows how many ideas in inference (M estimation, the bootstrap, semiparametrics, etc) repose on top of empirical process theory.
- Tsybakov, Alexandre B. (2008) “Introduction to Nonparametric Estimation” Springer.—Tools for obtaining lower bounds on estimators.
- B. Efron (2010) “Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction” Cambridge,.—A thought-provoking book.
- Bayesian Statistics
- Gelman, A. et al. (2003). “Bayesian Data Analysis” Chapman & Hall/CRC.—About Bayesian.
- Robert, C. and Casella, G. (2005). “Monte Carlo Statistical Methods” Springer.—about Bayesian computation.
- Probability Theory
- Grimmett, G. and Stirzaker, D. (2001). “Probability and Random Processes” Oxford.—Intermediate-level probability book.
- Pollard, D. (2001). “A User’s Guide to Measure Theoretic Probability” Cambridge.—More advanced level probability book.
- Durrett, R. (2005). “Probability: Theory and Examples” Duxbury.—Standard advanced probability book.
- Optimization
- Bertsimas, D. and Tsitsiklis, J. (1997). “Introduction to Linear Optimization” Athena.—A good starting book on linear optimization that will prepare you for convex optimization.
- Boyd, S. and Vandenberghe, L. (2004). “Convex Optimization” Cambridge.
- Y. Nesterov and Iu E. Nesterov (2003). “Introductory Lectures on Convex Optimization” Springer.—A start to understand lower bounds in optimization.
- Linear Algebra
- Golub, G., and Van Loan, C. (1996). “Matrix Computations” Johns Hopkins.—Getting a full understanding of algorithmic linear algebra is also important.
- Information Theory
- Cover, T. and Thomas, J. “Elements of Information Theory” Wiley.—Classic information theory.
- Functional Analysis
- Kreyszig, E. (1989). “Introductory Functional Analysis with Applications” Wiley.—Functional analysis is essentially linear algebra in infinite dimensions, and it’s necessary for kernel methods, for nonparametric Bayesian methods, and for various other topics.
Remarks from Professor Jordan: “not only do I think that you should eventually read all of these books (or some similar list that reflects your own view of foundations), but I think that you should read all of them three times—the first time you barely understand, the second time you start to get it, and the third time it all seems obvious.”
In mathematics, a general principle for studying an object is always from the study of the object itself to the study of the relationship between objects. In functional data analysis, the most important part for studying of the object itself, i.e. one functional data set, is functional principal component analysis (FPCA). And for the study of the relationship between two functional data sets, one popular way is various types of regression analysis. For this post, I only focus on the FPCA. The central idea of FPCA is dimension reduction by means of a spectral decomposition of the covariance operator, which yields functional principal components as coefficient vectors to represent the random curves in the sample.
First of all, let’s define what’s the FPCA. Suppose we observe functions 


is minimized. Once such a basis is found, we can replace each curve 




For FPCA, we usually adopt the so called “smooth-first-then-estimate” approach, namely,we first pre-process the discrete observations to get smoothed functional data by smoothing and then use the empirical estimators of the mean and covariance based on the smoothed functional data to conduct FPCA.
For the smoothing step, we have to consider individual by individual. For each realization, we can use basis expansion (Polynomial basis is unstable; Fourier basis is suitable for periodic functions; B-spline basis is flexible and useful), smoothing penalties (which lead to smoothing splines by the Smoothing Spline Theorem), as well as local polynomial smoothing:
- Basis expansion: by assuming one realization of the underlying true process
, where
are the basis functions, we have the estimation

- Smoothing penalties:
, where
is a measure for the roughness of functions.
- Local linear smoothing: assume at point
, we have
, then we have
estimated by the following
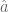

Once we have the smoothed functional data, denoted as 

And then we can have the empirical functional principal components as the eigenfunctions of the above sample covariance operator 


where
However, two common methods used in Statistics are described in Section 8.4 in the fundamental functional data analysis book written by Professors J. O. Ramsay and B. W. Silverman. One is the discretizing method and the other is the basis function method. For the discretizing method, essentially, we just discretize the smoothed functions 

- Basis expansion:
, and then
, where
and
;
- Covariance function:
;
- Eigenfunction expansion: assume the eigenfunction
;
- Problem Simplification: The above basis expansions lead to


where 



Note that the assumptions for the eigenfunctions to be orthonormal are equivalent to 


which is a traditional eigen problem for symmetric matrix 
Two special cases deserve particular attention. One is orthonormal basis which leads to 

Note that the empirical functional principal components are proved to be the eigenfunctions of the sample covariance operator. This fact connects the FPCA with the so called Karhunen-Lo

where 




So far, we only have discussed how to get the empirical functional principal components, i.e. eigenfunctions/orthonormal basis functions. But to represent the functional data, we have to get those coefficients, which are called FPC scores

Note that for the above estimation of the FPC scores via numerical integration, we first need the smoothed functional data
Degrees of freedom and information criteria are two fundamental concepts in statistical modeling, which are also taught in introductory statistics courses. But what are the exact abstract definitions for them which can be used to derive specific calculation formula in different situations.
I often use fit criteria like AIC and BIC to choose between models. I know that they try to balance good fit with parsimony, but beyond that I’m not sure what exactly they mean. What are they really doing? Which is better? What does it mean if they disagree? — Signed, Adrift on the IC’s
Intuitively, the degrees of freedom of a fitting procedure reflects the effective number of parameters used by the fitting procedure. Thus to most applied statisticians, a fitting procedure’s degrees of freedom is synonymous with its model complexity, or its capacity for overfitting to data. Is this really true? Regularization aims to improve prediction performance by trading an increase in training error for better agreement between training and prediction errors, which is often captured through decreased degrees of freedom. Is this always the case? When does more regularization imply fewer degrees of freedom?
For the above two questions, I think the most important thing is based on the following what-type question:
What are AIC and BIC? What is degrees of freedom?
Akaike’s Information Criterion (AIC) estimates the relative Kullback-Leibler (KL) distance of the likelihood function specified by a fitted candidate model, from the unknown true likelihood function that generated the data:

where 

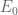



where 
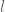



Schwarz’s Bayesian Information Criterion (BIC) is just comparing the posterior probability with the same prior and hence just comparing the likelihoods under different models:

which is just the Bayes factor. Schwarz showed that in many kinds of models 

which leads to the definition of BIC

In summary, AIC and BIC are both penalized-likelihood criteria. AIC is an estimate of a constant plus the relative distance between the unknown true likelihood function of the data and the fitted likelihood function of the model, so that a lower AIC means a model is considered to be closer to the truth. BIC is an estimate of a function of the posterior probability of a model being true, under a certain Bayesian setup, so that a lower BIC means that a model is considered to be more likely to be the true model. Both criteria are based on various assumptions and asymptotic approximations. Despite various subtle theoretical differences, their only difference in practice is the size of the penalty; BIC penalizes model complexity more heavily. The only way they should disagree is when AIC chooses a larger model than BIC. Thus, AIC always has a chance of choosing too big a model, regardless of n. BIC has very little chance of choosing too big a model if n is sufficient, but it has a larger chance than AIC, for any given n, of choosing too small a model.
The effective degrees of freedom for an arbitrary modelling approach is defined based on the concept of expected optimism:

where 







Why does this definition make sense? In fact, under some regularity conditions, Stein proved that

which can be regarded as a sensitivity measure of the fitted values to the observations.
In the linear model, we know that (Mallows) the relationship between the expected prediction error (EPE) and the residual sum of squares (RSS) follows

which leads to 
Here are some references on this topic:
-
Dziak, John J., et al. “Sensitivity and specificity of information criteria.” The Methodology Center and Department of Statistics, Penn State, The Pennsylvania State University (2012).
-
Janson, Lucas, Will Fithian, and Trevor Hastie. “Effective degrees of freedom: A flawed metaphor.” arXiv preprint arXiv:1312.7851 (2013).
- Tutorial: How to detect spurious correlations, and how to find the …
- Practical illustration of Map-Reduce (Hadoop-style), on real data
- Jackknife logistic and linear regression for clustering and predict…
- From the trenches: 360-degrees data science
- A synthetic variance designed for Hadoop and big data
- Fast Combinatorial Feature Selection with New Definition of Predict…
- A little known component that should be part of most data science a…
- 11 Features any database, SQL or NoSQL, should have
- Clustering idea for very large datasets
- Hidden decision trees revisited
- Correlation and R-Squared for Big Data
- Marrying computer science, statistics and domain expertize
- New pattern to predict stock prices, multiplies return by factor 5
- What Map Reduce can’t do
- Excel for Big Data
- Fast clustering algorithms for massive datasets
- Source code for our Big Data keyword correlation API
- The curse of big data
- How to detect a pattern? Problem and solution
- Interesting Data Science Application: Steganography
- Easily create documents from R with Rmarkdown
- How to publish R and ggplot2 to the web
- magrittr: Simplifying R code with pipes
- Updated dplyr Examples
- Video introduction to data manipulation with dplyr
- R and Data Science
- jiebaR中文分词——R的灵活,C的效率
- Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
- 41 hours of courses given in Iceland this Summer at the Machine Learning Summer School.
- summary of parallel machine learning approaches
- big data and data science talks

Recent Comments