
You are currently browsing the monthly archive for November 2014.
Recently some papers discussed in our journal club are focused on integrative clustering of multiple omics data sets. I found that they are all originated from factor analysis and make use of the advantage of factor analysis over principal component analysis.
Let’s recall the model for factor analysis:

where 





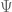






we can use the EM algorithm to get the MLE of the parameters 
Now for principal component analysis, for clarity, we are going to differentiate the classical (non-probabilistic) principal component analysis and probabilistic principal component analysis. The classical principal component analysis actually has no statistical model. And the probabilistic principal component model is defined as the above factor analysis model with 



where 




In applications, we just deal with the data matrix, 








Now think about what is the difference between the factor analysis and the probabilistic principal component analysis (PPCA). From the above definition, we see that the main difference is that factor analysis allow individual characteristics through the error term by 
with common structure 


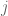
The AOAS 2013 paper is exactly using the above idea for modeling the integrative clustering:

where 


which is exactly a simple factor analysis. And this factor analysis model is more useful than PCA in this data integration setup just due to the allowing of individual characteristics for different data sources through 
The 2014 arXived paper is just generalizing the above paper by allowing another layer of individual characteristis:

But the problem for this one is how to do the estimation. Instead of using EM algorithm as used in the AOAS 2013 paper, they used the one as in the PCA by minimizing the reconstruction error.
On this Tuesday, Professor Xuming He presented their recent work on subgroup analysis, which is very interesting and useful in reality. Think about the following very much practical problem (since the drug is expensive or has certain amount of side effect):
If you are given the drug response, some baseline covariates which have nothing to do with the treatment, and the treatment indicator as well as some post-treatment measurements, how could you come up with a statistical model to tell whether there exist subgroups which respond to the treatment differently?
Think about 5 minutes and continue the following!
Dr He borrowed a very traditional model in Statistics, logistic-normal mixture model to study the above problem. The existence of the two subgroups is characterized by the observed baseline covariates, which have nothing to do with the treatment:

where 

with different means 




Nice work to demonstrate how to come up with a statistical model to study some interesting and practical problems!
But the above part has nothing to do with the title, EM algorithm. Actually you could imagine that they will use EM as a basic tool to study the above mixture model. That’s why I came back to revisit this great idea in Statistics.
Given complete random vector 
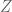



where the last inequality is from Jensen’s inequality, and 


Then we have


In summary, we have the following EM procedure:
- E step: get the conditional distribution
;
- M step:

And the corresponding EM algorithm can be described as the following iterative procedure:
- E step: get the conditional distribution
;
- M step:

In order to make this procedure effective, in the M step, the condition expectation should be easy to calculate. In fact, usually, since the expectation will be taken under the current 



And this procedure guarantees the following to make sure the convergence


In summary, EM algorithm is useful when the marginal problem 


In the talk given by Professor Xuming He, he mentioned a rule of thumb from practice experience that the EM algorithm produces a good enough estimator in the first few steps.
The core idea of Empirical Likelihood (EL) is to use a maximum entropy discrete distribution supported on the data points and constrained by estimating equations related with the parameters of interest. As such, it is a non-parametric approach in the sense that the distribution of the data does not need to be specified, only some of its characteristics usually via moments. In short, it’s a non-parametric likelihood, which is fundamental for the likelihood-based statistical methodology.
Bayesian Analysis is a very popular and useful method in applications. As we discussed in the last post, it’s essentially an belief updating procedure through data, which is very natural in modeling. Last time, I said I did not get why there is a severe debate between Frequentist and Bayesian. Yesterday, I had a nice talk with Professor Xuming He from University of Michigan. When we talked about the Bayesian analysis, he made a nice point that in Frequentist analysis, the model mis-specification can be addressed in a very rigorous way to conduct valid statistical inference; while in Bayesian analysis, it is very sensitive to the likelihood as well as the prior, but how to do the adjustment is a big problem (here is a paper discussing model misspecification problems under Bayesian framework).
Before the discussion with Dr. Xuming He, intuitively, I thought it’s very natural and potentially very useful to combine empirical likelihood with Bayesian analysis by regarding empirical likelihood as the likelihood used in the Bayesian framework. But now I got to understand the importance of why Professor Nicole Lazar from University of Georgia had a paper on “Bayesian Empirical Likelihood” to discuss the validity of posterior inference: “…can likelihoods other than the density from which the data are assumed to be generated be used as the likelihood portion in a Bayesian analysis?” And the paper concluded that “…while they indicate that it is feasible to consider a Bayesian inferential procedure based on replacing the data likelihood with empirical likelihood, the validity of the posterior inference needs to be established for each case individually.”
But Professor Xuming He made a nice comment that Bayesian framework can be used to avoid the calculation of maximum empirical likelihood estimator by proving of the asymptotically normal posterior distribution with mean around the maximum empirical likelihood estimator. The original idea of their AOS paper was indeed to use the computational advantage from Bayesian side to solve the optimization difficulty in getting maximum empirical likelihood estimator. This reminded me of another paper about “Approximate Bayesian Computation (ABC) via Empirical Likelihood“, which used empirical likelihood to get improvement in the approximation at an overall computing cost that is negligible against ABC.
We know that for general Bayesian analysis, the goal is to be able to simulate from the posterior distribution by using MCMC for example. But in order to use MCMC to simulate from the posterior distribution, we need to be able to evaluate the likelihood. But sometimes, it’s hard to evaluate the likelihood due to the complexity of the model. For example, recently laundry socks problem is a hit online. Since it’s not that trivial to figure out the the likelihood of the process although we have a simple generative model from which we can easily simulate samples, Professor Rasmus Bååth presented a Bayesian analysis by using ABC. Later Professor Christian Robert presented exact ptobability calculations pointing out that Feller had posed a similar problem. And here is another post from Professor Saunak Sen. The basic idea for ABC approximation is to accept values provided the simulated sample is sufficiently close to the observed data point:
- Simulate
, where
is the prior;
- Simulate
from the generative model;
- If
is small, keep
is observed data point. Otherwise reject.
Now how to use empirical likelihood to help ABC? Actually although the original motivation is the same, that is to approximate the likelihood (ABC approximate the likelihood via simulation and empirical likelihood version of ABC is to use empirical likelihood to approximate the true likelihood), it’s more natural to start from the original Bayesian computation (this is also why Professor Christian Robert changed the title of their paper). For the posterior sample, we can generate as the following from the importance sampling perspective:
- Simulate
- Get the corresponding importance weight as
where
is the likelihood.
Now if we do not know the likelihood, we can do the following:
- Simulate
- Get the corresponding importance weight as
where
is the empirical likelihood.
This is the way of doing Bayesian computation via empirical likelihood.
The main difference between Bayesian computation via empirical likelihood and Empirical likelihood Bayesian is that the first one use empirical likelihood to approximate the likelihood in the Bayesian computation and followed by Bayesian inference, while the second one is that use Bayesian computation to overcome the optimization difficulty and followed by studying of the frequentist property.
updated[4/28/2015]: Here is a nice post talking about the issue for the Bayesian, especially for the model misspecification.
Last night, I had a discussion about the integrative data analysis (closely related with the discussion of AOAS 2014 paper from Dr Xihong Lin’s group and JASA 2014 paper from Dr. Hongzhe Li’s group) with my friend. If some biologist gave you the genetic variants (e.g. SNP) data and the phenotype (e.g. some trait) data, you were asked to do the association analysis to identify the genetic variants which is significantly associated with the trait. One year later, the biologist got some additional data such as gene expression data which are related with the two data sets given before, and you are now asked to calibrate your analysis to detect the association more efficiently and powerfully by integrating the three data sources. In this data rich age, it’s quite natural to get into this situation in practice. The question is how to come up with a natural and useful statistical framework to deal with such data integration.
For simplicity, we considered the problem that if you are first given two random variables, 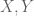


where
- What if
- What if
After thinking about these, you will find that for
In order to see why, first notice that the problem exactly depends on how to understand the following multiple linear regression problem:

Now from the multiple linear regression knowledge, we have

where 


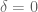

Now please think about the question:
What is the difference between doing univariate regression one by one and doing multiple linear regression all at once?
Here is some hint: first we regress

And then on one hand we find that 


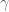
![Y-E(Y|X)=\gamma [Z-E(Z|X)]+\varepsilon.](https://s0.wp.com/latex.php?latex=Y-E%28Y%7CX%29%3D%5Cgamma+%5BZ-E%28Z%7CX%29%5D%2B%5Cvarepsilon.&bg=ffffff&fg=545454&s=0&c=20201002)
This procedure actually is explaining what is the multiple linear regression and what is the meaning for the coefficients (think about the meaning of

Recent Comments