
You are currently browsing the monthly archive for January 2015.
The first colloquium speaker at this semester, professor Wei Zheng from IUPUI, will give a talk on “Universally optimal designs for two interference models“. In this data explosive age, people are easy to get big data set, which renders people difficult to make inferences from such massive data. Since people usually think that with more data, they have more chance to get more useful information from them, lots of researchers are struggling to achieve methodological advancements under this setup. This is a very challenging research area and of course very important, which in my opinion needs the resurgence of mathematical statistics by borrowing great ideas from various mathematical fields. However, another great and classical statistical research area should come back again to help statistical inference procedures from the beginning stage of data analysis, collecting data by design of experiments so that we can control the data quality, usefulness and size. Thus it’s necessary for us to know what is optimal design of experiments. Here is an introduction to this interesting topic.
In statistics, we have to organize an experiment in order to gain some information about an object of interest. Fragments of this information can be obtained by making observations within some elementary experiments called trials. The set of all trials which can be incorporated in a prepared experiment will be denoted by 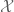

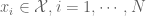
We shall restrict our attention to the parametric situation in the case of a regression model, the mean response function is then parameterized as
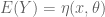
specifying for a particular 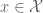

A design is specified by an initially arbitrary measure 

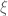
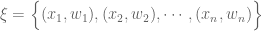
where the 



where 

Now we have to propose the statistical criteria for the optimum. It is known that the least squares estimator minimizes the variance of mean-unbiased estimators (under the conditions of the Gauss–Markov theorem). In the estimation theory for statistical models with one real parameter, the reciprocal of the variance of an (“efficient”) estimator is called the “Fisher information” for that estimator. Because of this reciprocity, minimizing the variance corresponds to maximizing the information. When the statistical model has several parameters, however, the mean of the parameter-estimator is a vector and its variance is a matrix. The inverse matrix of the variance-matrix is called the “information matrix”. Because the variance of the estimator of a parameter vector is a matrix, the problem of “minimizing the variance” is complicated. Using statistical theory, statisticians compress the information-matrix using real-valued summary statistics; being real-valued functions, these “information criteria” can be maximized. The traditional optimality-criteria are invariants of the information matrix; algebraically, the traditional optimality-criteria are functionals of the eigenvalues of the information matrix.
- A-optimality (“average” or trace)
- One criterion is A-optimality, which seeks to minimize the trace of the inverse of the information matrix. This criterion results in minimizing the average variance of the estimates of the regression coefficients.
- D-optimality (determinant)
- A popular criterion is D-optimality, which seeks to maximize the determinant of the information matrix of the design. This criterion results in maximizing the differential Shannon information content of the parameter estimates.
- E-optimality (eigenvalue)
- Another design is E-optimality, which maximizes the minimum eigenvalue of the information matrix.
- T-optimality
- This criterion maximizes the trace of the information matrix.
Other optimality-criteria are concerned with the variance of predictions:
- G-optimality
- A popular criterion is G-optimality, which seeks to minimize the maximum entry in the diagonal of the hat matrix. This has the effect of minimizing the maximum variance of the predicted values.
- I-optimality (integrated)
- A second criterion on prediction variance is I-optimality, which seeks to minimize the average prediction variance over the design space.
- V-optimality (variance)
- A third criterion on prediction variance is V-optimality, which seeks to minimize the average prediction variance over a set of m specific points.
Now back to our example, because the asymptotic covariance matrix associated with the LSE of 

and G-optimality seeks to minimize 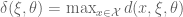
A central result in the theory of optimal design, the General Equivalence Theorem, asserts that the design 

the number of parameters.
Now the optimal design for an interference model, professor Wei Zheng will talk about, considers the following model in the block designs with neighbor effects:
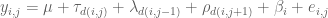
where 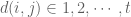

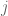

is the general mean;
is the direct effect of treatment
;
and
are respectively the left and right neighbor effects; that’s the interference effect of the treatment assigned to, respectively, the left and right neighbor plots
and
.
is the effect of the
is the random error,
.
We seed the optimal design among designs 



I am not going into the details of the derivation of the optimal design for the above interference model. I just sketch the outline here. First of all we can write down the information matrix for the direct treatment effect 


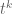

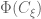
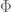
for any permutation matrix
;
is nondecreasing in the scalar
.
A measure 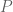

Recent Comments