
You are currently browsing the category archive for the ‘Mathematics’ category.
- A nice blog on CS including learnings: https://blog.acolyer.org/ called “the morning paper”: an interesting/influential/important paper from the world of CS every weekday morning, as selected by Adrian Colyer. I hope there is a similar blog on Statistics, reviewing and recommending an interesting/influential/important paper from the world of Statistics.
- A wonderful summary of Mathematical Tricks Commonly Used in Machine Learning and Statistics with examples
- I just realized that when I teach ridge regression I should have used A Useful Matrix Inverse Equality for Ridge Regression
- GANs should be gained much attention in the stats community: Understanding Generative Adversarial Networks. This is a nice post about GANs based on “probably the highest-quality general overview available nowadays: Ian Goodfellow’s tutorial on arXiv, which he then presented in some form at NIPS 2016. “
- R or Python? Why not both? Using Anaconda Python within R with {reticulate}
- “A heatmap is basically a table that has colors in place of numbers. Colors correspond to the level of the measurement.”
The first colloquium speaker at this semester, professor Wei Zheng from IUPUI, will give a talk on “Universally optimal designs for two interference models“. In this data explosive age, people are easy to get big data set, which renders people difficult to make inferences from such massive data. Since people usually think that with more data, they have more chance to get more useful information from them, lots of researchers are struggling to achieve methodological advancements under this setup. This is a very challenging research area and of course very important, which in my opinion needs the resurgence of mathematical statistics by borrowing great ideas from various mathematical fields. However, another great and classical statistical research area should come back again to help statistical inference procedures from the beginning stage of data analysis, collecting data by design of experiments so that we can control the data quality, usefulness and size. Thus it’s necessary for us to know what is optimal design of experiments. Here is an introduction to this interesting topic.
In statistics, we have to organize an experiment in order to gain some information about an object of interest. Fragments of this information can be obtained by making observations within some elementary experiments called trials. The set of all trials which can be incorporated in a prepared experiment will be denoted by 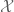

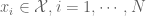
We shall restrict our attention to the parametric situation in the case of a regression model, the mean response function is then parameterized as
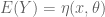
specifying for a particular 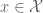

A design is specified by an initially arbitrary measure 

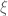
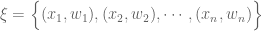
where the 



where 

Now we have to propose the statistical criteria for the optimum. It is known that the least squares estimator minimizes the variance of mean-unbiased estimators (under the conditions of the Gauss–Markov theorem). In the estimation theory for statistical models with one real parameter, the reciprocal of the variance of an (“efficient”) estimator is called the “Fisher information” for that estimator. Because of this reciprocity, minimizing the variance corresponds to maximizing the information. When the statistical model has several parameters, however, the mean of the parameter-estimator is a vector and its variance is a matrix. The inverse matrix of the variance-matrix is called the “information matrix”. Because the variance of the estimator of a parameter vector is a matrix, the problem of “minimizing the variance” is complicated. Using statistical theory, statisticians compress the information-matrix using real-valued summary statistics; being real-valued functions, these “information criteria” can be maximized. The traditional optimality-criteria are invariants of the information matrix; algebraically, the traditional optimality-criteria are functionals of the eigenvalues of the information matrix.
- A-optimality (“average” or trace)
- One criterion is A-optimality, which seeks to minimize the trace of the inverse of the information matrix. This criterion results in minimizing the average variance of the estimates of the regression coefficients.
- D-optimality (determinant)
- A popular criterion is D-optimality, which seeks to maximize the determinant of the information matrix of the design. This criterion results in maximizing the differential Shannon information content of the parameter estimates.
- E-optimality (eigenvalue)
- Another design is E-optimality, which maximizes the minimum eigenvalue of the information matrix.
- T-optimality
- This criterion maximizes the trace of the information matrix.
Other optimality-criteria are concerned with the variance of predictions:
- G-optimality
- A popular criterion is G-optimality, which seeks to minimize the maximum entry in the diagonal of the hat matrix. This has the effect of minimizing the maximum variance of the predicted values.
- I-optimality (integrated)
- A second criterion on prediction variance is I-optimality, which seeks to minimize the average prediction variance over the design space.
- V-optimality (variance)
- A third criterion on prediction variance is V-optimality, which seeks to minimize the average prediction variance over a set of m specific points.
Now back to our example, because the asymptotic covariance matrix associated with the LSE of 

and G-optimality seeks to minimize 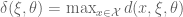
A central result in the theory of optimal design, the General Equivalence Theorem, asserts that the design 

the number of parameters.
Now the optimal design for an interference model, professor Wei Zheng will talk about, considers the following model in the block designs with neighbor effects:
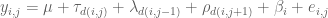
where 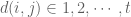

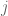

is the general mean;
is the direct effect of treatment
;
and
are respectively the left and right neighbor effects; that’s the interference effect of the treatment assigned to, respectively, the left and right neighbor plots
and
.
is the effect of the
is the random error,
.
We seed the optimal design among designs 



I am not going into the details of the derivation of the optimal design for the above interference model. I just sketch the outline here. First of all we can write down the information matrix for the direct treatment effect 


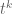

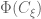
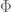
for any permutation matrix
;
is nondecreasing in the scalar
.
A measure 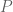
There has been a Machine Learning (ML) reading list of books in hacker news for a while, where Professor Michael I. Jordan recommend some books to start on ML for people who are going to devote many decades of their lives to the field, and who want to get to the research frontier fairly quickly. Recently he articulated the relationship between CS and Stats amazingly well in his recent reddit AMA, in which he also added some books that dig still further into foundational topics. I just list them here for people’s convenience and my own reference.
- Frequentist Statistics
- Casella, G. and Berger, R.L. (2001). “Statistical Inference” Duxbury Press.—Intermediate-level statistics book.
- Ferguson, T. (1996). “A Course in Large Sample Theory” Chapman & Hall/CRC.—For a slightly more advanced book that’s quite clear on mathematical techniques.
- Lehmann, E. (2004). “Elements of Large-Sample Theory” Springer.—About asymptotics which is a good starting place.
- Vaart, A.W. van der (1998). “Asymptotic Statistics” Cambridge.—A book that shows how many ideas in inference (M estimation, the bootstrap, semiparametrics, etc) repose on top of empirical process theory.
- Tsybakov, Alexandre B. (2008) “Introduction to Nonparametric Estimation” Springer.—Tools for obtaining lower bounds on estimators.
- B. Efron (2010) “Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction” Cambridge,.—A thought-provoking book.
- Bayesian Statistics
- Gelman, A. et al. (2003). “Bayesian Data Analysis” Chapman & Hall/CRC.—About Bayesian.
- Robert, C. and Casella, G. (2005). “Monte Carlo Statistical Methods” Springer.—about Bayesian computation.
- Probability Theory
- Grimmett, G. and Stirzaker, D. (2001). “Probability and Random Processes” Oxford.—Intermediate-level probability book.
- Pollard, D. (2001). “A User’s Guide to Measure Theoretic Probability” Cambridge.—More advanced level probability book.
- Durrett, R. (2005). “Probability: Theory and Examples” Duxbury.—Standard advanced probability book.
- Optimization
- Bertsimas, D. and Tsitsiklis, J. (1997). “Introduction to Linear Optimization” Athena.—A good starting book on linear optimization that will prepare you for convex optimization.
- Boyd, S. and Vandenberghe, L. (2004). “Convex Optimization” Cambridge.
- Y. Nesterov and Iu E. Nesterov (2003). “Introductory Lectures on Convex Optimization” Springer.—A start to understand lower bounds in optimization.
- Linear Algebra
- Golub, G., and Van Loan, C. (1996). “Matrix Computations” Johns Hopkins.—Getting a full understanding of algorithmic linear algebra is also important.
- Information Theory
- Cover, T. and Thomas, J. “Elements of Information Theory” Wiley.—Classic information theory.
- Functional Analysis
- Kreyszig, E. (1989). “Introductory Functional Analysis with Applications” Wiley.—Functional analysis is essentially linear algebra in infinite dimensions, and it’s necessary for kernel methods, for nonparametric Bayesian methods, and for various other topics.
Remarks from Professor Jordan: “not only do I think that you should eventually read all of these books (or some similar list that reflects your own view of foundations), but I think that you should read all of them three times—the first time you barely understand, the second time you start to get it, and the third time it all seems obvious.”
Last night, I had a discussion about the integrative data analysis (closely related with the discussion of AOAS 2014 paper from Dr Xihong Lin’s group and JASA 2014 paper from Dr. Hongzhe Li’s group) with my friend. If some biologist gave you the genetic variants (e.g. SNP) data and the phenotype (e.g. some trait) data, you were asked to do the association analysis to identify the genetic variants which is significantly associated with the trait. One year later, the biologist got some additional data such as gene expression data which are related with the two data sets given before, and you are now asked to calibrate your analysis to detect the association more efficiently and powerfully by integrating the three data sources. In this data rich age, it’s quite natural to get into this situation in practice. The question is how to come up with a natural and useful statistical framework to deal with such data integration.
For simplicity, we considered the problem that if you are first given two random variables, 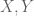
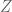



where 
- What if
- What if
After thinking about these, you will find that for
In order to see why, first notice that the problem exactly depends on how to understand the following multiple linear regression problem:

Now from the multiple linear regression knowledge, we have

where 


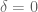

Now please think about the question:
What is the difference between doing univariate regression one by one and doing multiple linear regression all at once?
Here is some hint: first we regress

And then on one hand we find that 


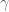
![Y-E(Y|X)=\gamma [Z-E(Z|X)]+\varepsilon.](https://s0.wp.com/latex.php?latex=Y-E%28Y%7CX%29%3D%5Cgamma+%5BZ-E%28Z%7CX%29%5D%2B%5Cvarepsilon.&bg=ffffff&fg=545454&s=0&c=20201002)
This procedure actually is explaining what is the multiple linear regression and what is the meaning for the coefficients (think about the meaning of
- Interview with Nick Chamandy, statistician at Google
- You and Your Research + video
- Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained
- A Survival Guide to Starting and Finishing a PhD
- Six Rules For Wearing Suits For Beginners
- Why I Created C++
- More advice to scientists on blogging
- Software engineering practices for graduate students
- Statistics Matter
- What statistics should do about big data: problem forward not solution backward
- How signals, geometry, and topology are influencing data science
- The Bounded Gaps Between Primes Theorem has been proved
- A non-comprehensive list of awesome things other people did this year.
- Jake VanderPlas writes about the Big Data Brain Drain from academia.
- Tomorrow’s Professor Postings
- Best Practices for Scientific Computing
- Some tips for new research-oriented grad students
- 3 Reasons Every Grad Student Should Learn WordPress
- How to Lie With Statistics (in the Age of Big Data)
- The Geometric View on Sparse Recovery
- The Mathematical Shape of Things to Come
- A Guide to Python Frameworks for Hadoop
- Statistics, geometry and computer science.
- How to Collaborate On GitHub
- Step by step to build my first R Hadoop System
- Open Sourcing a Python Project the Right Way
- Data Science MD July Recap: Python and R Meetup
- git 最近感悟
- 10 Reasons Python Rocks for Research (And a Few Reasons it Doesn’t)
- Effective Presentations – Part 2 – Preparing Conference Presentations
- Doing Statistical Research
- How to Do Statistical Research
- Learning new skills
- How to Stand Out When Applying for An Academic Job
- Maturing from student to researcher
- False discovery rate regression (cc NSA’s PRISM)
- Job Hunting Advice, Pt. 3: Networking
- Getting Started with Git
This is from a post Connected objects and a reconstruction theorem:
A common theme in mathematics is to replace the study of an object with the study of some category that can be built from that object. For example, we can
- replace the study of a group
with the study of its categoryof linear representations,
- replace the study of a ring
with the study of its category
of
- replace the study of a topological space
with the study of its category
of sheaves,

and so forth. A general question to ask about this setup is whether or to what extent we can recover the original object from the category. For example, if 
Python is great and I think will be also great. For pure mathematics, it has lots of symbol calculations, since pure mathematics is abstract and powerful, like differential geometry, commutative algebra, algebraic geometry, and so on. However, science is nothing but experiment and computation. We also need powerful computational software to help us to carry out the result by powerful computation. Sage is your choice ! Since Sage claims that
Sage is a free open-source mathematics software system licensed under the GPL. It combines the power of many existing open-source packages into a common Python-based interface.Mission: Creating a viable free open source alternative to Magma, Maple, Mathematica and Matlab.
Not only for pure mathematics, today I happened to see a blog post about using Sage to calculate high moments of Gaussian:
var('m, s, t')mgf(t) = exp(m*t + t^2*s^2/2)for i in range(1, 11):derivative(mgf, t, i).subs(t=0)
which leads to the following result:
mm^2 + s^2m^3 + 3*m*s^2m^4 + 6*m^2*s^2 + 3*s^4m^5 + 10*m^3*s^2 + 15*m*s^4m^6 + 15*m^4*s^2 + 45*m^2*s^4 + 15*s^6m^7 + 21*m^5*s^2 + 105*m^3*s^4 + 105*m*s^6m^8 + 28*m^6*s^2 + 210*m^4*s^4 + 420*m^2*s^6 + 105*s^8m^9 + 36*m^7*s^2 + 378*m^5*s^4 + 1260*m^3*s^6 + 945*m*s^8m^10 + 45*m^8*s^2 + 630*m^6*s^4 + 3150*m^4*s^6 + 4725*m^2*s^8 + 945*s^10
Go Python! Go Sage!
Today, there will be a talk, Imaginary Geometry and the Gaussian Free Field, given by Jason Miller from Microsoft Research. I just googled it and found the following interesting materials:
- Gaussian free fields for mathematicians
- Gaussian free field and conformal field theory: In these expository lectures, it gives an elementary introduction to conformal field theory in the context of probability theory and complex analysis. It considers statistical fields, and defines Ward functionals in terms of their Lie derivatives. Based on this approach, it explains some equations of conformal field theory and outline their relation to SLE theory.
- SLE and the free field: Partition functions and couplings
- Schramm-Loewner evolution (SLE). See slides by Tom Alberts and 2006 ICM slides by Oded Schramm and St. Flour Lecture Notes by Wendelin Werner . See also Ito’s lemma notes .
There will be a talk, “Landscape of Random Functions in Many Dimensions via Random Matrix Theory”, next week given by Antonio Auffinger from the University of Chicago.
Abstract: How many critical values a typical Morse function have on a high dimensional manifold? Could we say anything about the topology of its level sets? In this talk I will survey a joint work with Gerard Ben Arous and Jiri Cerny that addresses these questions in a particular but fundamental example. We investigate the landscape of a general Gaussian random smooth function on the N-dimensional sphere. These corresponds to Hamiltonians of well-known models of statistical physics, i.e spherical spin glasses. Using the classical Kac-Rice formula, this counting boils down to a problem in Random Matrix Theory. This allows us to show an interesting picture for the complexity of these random Hamiltonians, for the bottom of the energy landscape, and in particular a strong correlation between the index and the critical value. We also propose a new invariant for the possible transition between the so-called 1-step replica symmetry breaking and a Full Replica symmetry breaking scheme and show how the complexity function is related to the Parisi functional.
This topic is kind of a combination of my majors, differential geometry, probability and statistics. I am interested in this although I can imagine that it is hard.
Since I missed the whole summer, but during the summer, many interesting things happened, I have to make it up. So this post will be updated during the next few days. I will collect some posts from others here. I hope it would be helpful for you.
2, Interesting Neural Network Papers at ICML 2011
3, Interesting papers at COLT 2011
4, The conference(s) post: ACL and ICML
5, 14th International Conference on Artificial Intelligence and Statistics 2011 –Ft.Lauderdale

Recent Comments