
You are currently browsing the category archive for the ‘Statistics’ category.
. . . the objective of statistical methods is the reduction of data. A quantity of data. . . is to be replaced by relatively few quantities which shall adequately represent. . . the
relevant information contained in the original data.Since the number of independent facts supplied in the data is usually far greater than the number of facts sought, much of the information supplied by an actual sample is irrelevant. It is the object of the statistical process employed in the reduction of data to exclude this irrelevant information, and to isolate the whole of the relevant information contained in the data.
—Fisher’s 1922 article “On the mathematical foundations of theoretical statistics”
Sufficiency is the concept to keep relevant information for the estimation of the target parameter. Since the raw data is of course sufficient, we will look for minimal (i.e. maximal reduction) and sufficient statistic. A minimal sufficient statistic may still contain some redundancy. In other words, there may be more than one way to estimate the parameter. Essentially, completeness says the only way to estimate 0 is with 0. If T is not complete, then it somehow can be used to estimate the same quantity two different ways.
Note that a further reduction of complete statistic is also complete. Hence the key point of completeness is that it indicates a reduction of the data to the point where there can be at most one unbiased estimator of any 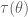
![E_{\theta}g_j(T)=\tau(\theta), j=1,2\Rightarrow E_{\theta}[g_1(T)-g_2(T)]=0,\forall\theta\Rightarrow g_1=g_2](https://s0.wp.com/latex.php?latex=E_%7B%5Ctheta%7Dg_j%28T%29%3D%5Ctau%28%5Ctheta%29%2C+j%3D1%2C2%5CRightarrow+E_%7B%5Ctheta%7D%5Bg_1%28T%29-g_2%28T%29%5D%3D0%2C%5Cforall%5Ctheta%5CRightarrow+g_1%3Dg_2&bg=ffffff&fg=545454&s=0&c=20201002)
Thus with the reduction keeping sufficiency, once it reaches completeness, we know that this sufficient and complete statistic is minimal sufficient if there exists one.
Here is a very nice geometric interpretation of completeness: https://stats.stackexchange.com/q/285503
- A nice blog on CS including learnings: https://blog.acolyer.org/ called “the morning paper”: an interesting/influential/important paper from the world of CS every weekday morning, as selected by Adrian Colyer. I hope there is a similar blog on Statistics, reviewing and recommending an interesting/influential/important paper from the world of Statistics.
- A wonderful summary of Mathematical Tricks Commonly Used in Machine Learning and Statistics with examples
- I just realized that when I teach ridge regression I should have used A Useful Matrix Inverse Equality for Ridge Regression
- GANs should be gained much attention in the stats community: Understanding Generative Adversarial Networks. This is a nice post about GANs based on “probably the highest-quality general overview available nowadays: Ian Goodfellow’s tutorial on arXiv, which he then presented in some form at NIPS 2016. “
- R or Python? Why not both? Using Anaconda Python within R with {reticulate}
- “A heatmap is basically a table that has colors in place of numbers. Colors correspond to the level of the measurement.”
You can install the StatRep package by downloading statrep.zip from support.sas.com/StatRepPackage, which contains:
- doc/statrepmanual.pdf – The StatRep User’s Guide (this manual)
- doc/quickstart.tex – A template and tutorial sample LATEX file
- sas/statrep_macros.sas – The StatRep SAS macros
- sas/statrep_tagset.sas – The StatRep SAS tagset for LaTeX tabular output
- statrep.ins – The LATEX package installer file
- statrep.dtx – The LATEX package itself
Unzip the file statrep.zip to a temporary directory and perform the following steps:
- Step 1: Install the StatRep SAS Macros: Copy the file statrep_macros.sas to a local directory. If you have a folder where you keep your personal set of macros, copy the file there. Otherwise, create a directory such as C:\mymacros and copy the file into that directory.
- Step 2: Install the StatRep LaTeX Package: These instructions show how to install the StatRep package in your LATEX distribution for your personal use.
- a. For MikTEX users: If you do not have a directory for your own packages, choose a directory name to contain your packages (for example, C:\localtexmf). In the following instructions, this directory is referred to as the “root directory”.
- b. Create the additional subdirectories under the above root directory: tex/latex/statrep. Your directory tree will have the following structure: root directory/tex/latex/statrep.
- c. Copy the files statrep.dtx, statrep.ins, statrepmanual.pdf, and statrepmanual.tex to the statrep subdirectory.
- d. In the command prompt, cd to the statrep directory and enter the following command: pdftex statrep.insThe command creates several files, one of which is the configuration file, statrep.cfg.
- Step 3: Tell the StatRep Package the Location of the StatRep SAS Macros. Edit the statrep.cfg file that was generated in Step 2d so that the macro \SRmacropath contains the correct location of the macro file from step 1. For example, if you copied the statrep_macros.sas file to a directory named C:\mymacros, then you de- fine macro \SRmacropath as follows: \def\SRmacropath{C:/mymacros/statrep_macros.sas} Use the forward slash as the directory name delimiter instead of the backslash, which is a special character in LaTeX.
You can now test and experiment with the package. Create a working directory, and copy the file quickstart.tex into it. To generate the quick-start document:
- Compile the document with pdfLATEX. You can use a LATEX-aware editor such as TEXworks, or use the command-line command pdflatex. This step generates the SAS program that is needed to produce the results.
- Execute the SAS program quickstart_SR.sas, which was automatically created in the preceding step. This step generates the SAS results that are requested in the quick-start document.
- Recompile the document with pdfLATEX. This step compiles the quick-start document to PDF, this time including the SAS results that were generated in the preceding step. In some cases listing outputs may not be framed properly after this step. If your listing outputs are not framed properly, repeat this step so that LaTeX can remeasure the listing outputs.
Please refer to the following file for detailed information:
Click to access statrepmanual.pdf
Yesterday I learned something interesting from a talk given by Professor Bikas K Sinha. The following is an excerpt from the reference [1], which exactly shows the interesting point of the problem.
“A population consisting of an unknown number of distinct species is searched by selecting one member at a time. No a priori information is available concerning the probability that an object selected from this population will represent a particular species. Based on the information available after an n-stage search it is desired to predict the conditional probability that the next selection will represent a species not represented in the n-stage sample.”
Searcher: “I am contemplating extending my initial search an additional m stages, and will so do if the expected number of individuals I will select in the second search who are new species is large. What do you recommend?”
Statistician: “Make one more search and then I will tell you.”
Refer to the Annals of Statistics paper:
[1] Starr, Norman. “Linear estimation of the probability of discovering a new species.” The Annals of Statistics (1979): 644-652.
Recently I was referred to a nice article talking about the relationship between Statistics and data science. Here is my feedback to share with you:
- First of all, Statistics is a science dealing with data, including five main components, data collection (design of experiment, sampling), data preparation (storage, reading, organization, cleaning), exploratory data analysis (numerical summarization, visualization), statistical inference (frequentist and Bayesian) and communication (interpretation).
- It’s statistician’s mistake putting extremely unequal weights on the development of the five components in the past 50 years, mostly focusing on the fourth component.
- Fortunately, the first component is now showing resurgence under the massive data situation. How to sample the “influential” data points from massive samples is a big and important research topic.
- People outside of traditional statistics community have been picking up the second and third components, like adopting the two undeveloped statistics children. And the adoptive parents are saying that the two children are not statistics, and instead they call them data science.
- But Statistics is really about all of the five equally important components.
- And our Statistician’s goal is to get the two children back to our statistics community. We are all Statistician!
- Deep Learning Master Class
- Advances in Variational Inference
- Numerical Optimization: Understanding L-BFGS
- An exact mapping between the Variational Renormalization Group and Deep Learning
- New ASA Guidelines for Undergraduate Statistics Programs
- 奇异值分解(We Recommend a Singular Value Decomposition)
- 如何简单形象又有趣地讲解神经网络是什么?
- Academic vs. Industry Careers
- Hadley Wickham: Impact the world by being useful
- Statisticians in World War II: They also served
- A Brief Overview of Deep Learning
- Advice for applying Machine Learning
- Deep Learning Tutorial
- Gibbs Sampling in Haskell
- How-to go parallel in R – basics + tips
The first colloquium speaker at this semester, professor Wei Zheng from IUPUI, will give a talk on “Universally optimal designs for two interference models“. In this data explosive age, people are easy to get big data set, which renders people difficult to make inferences from such massive data. Since people usually think that with more data, they have more chance to get more useful information from them, lots of researchers are struggling to achieve methodological advancements under this setup. This is a very challenging research area and of course very important, which in my opinion needs the resurgence of mathematical statistics by borrowing great ideas from various mathematical fields. However, another great and classical statistical research area should come back again to help statistical inference procedures from the beginning stage of data analysis, collecting data by design of experiments so that we can control the data quality, usefulness and size. Thus it’s necessary for us to know what is optimal design of experiments. Here is an introduction to this interesting topic.
In statistics, we have to organize an experiment in order to gain some information about an object of interest. Fragments of this information can be obtained by making observations within some elementary experiments called trials. The set of all trials which can be incorporated in a prepared experiment will be denoted by 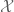

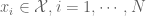
We shall restrict our attention to the parametric situation in the case of a regression model, the mean response function is then parameterized as
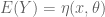
specifying for a particular 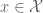

A design is specified by an initially arbitrary measure 

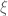
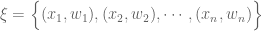
where the 



where 

Now we have to propose the statistical criteria for the optimum. It is known that the least squares estimator minimizes the variance of mean-unbiased estimators (under the conditions of the Gauss–Markov theorem). In the estimation theory for statistical models with one real parameter, the reciprocal of the variance of an (“efficient”) estimator is called the “Fisher information” for that estimator. Because of this reciprocity, minimizing the variance corresponds to maximizing the information. When the statistical model has several parameters, however, the mean of the parameter-estimator is a vector and its variance is a matrix. The inverse matrix of the variance-matrix is called the “information matrix”. Because the variance of the estimator of a parameter vector is a matrix, the problem of “minimizing the variance” is complicated. Using statistical theory, statisticians compress the information-matrix using real-valued summary statistics; being real-valued functions, these “information criteria” can be maximized. The traditional optimality-criteria are invariants of the information matrix; algebraically, the traditional optimality-criteria are functionals of the eigenvalues of the information matrix.
- A-optimality (“average” or trace)
- One criterion is A-optimality, which seeks to minimize the trace of the inverse of the information matrix. This criterion results in minimizing the average variance of the estimates of the regression coefficients.
- D-optimality (determinant)
- A popular criterion is D-optimality, which seeks to maximize the determinant of the information matrix of the design. This criterion results in maximizing the differential Shannon information content of the parameter estimates.
- E-optimality (eigenvalue)
- Another design is E-optimality, which maximizes the minimum eigenvalue of the information matrix.
- T-optimality
- This criterion maximizes the trace of the information matrix.
Other optimality-criteria are concerned with the variance of predictions:
- G-optimality
- A popular criterion is G-optimality, which seeks to minimize the maximum entry in the diagonal of the hat matrix. This has the effect of minimizing the maximum variance of the predicted values.
- I-optimality (integrated)
- A second criterion on prediction variance is I-optimality, which seeks to minimize the average prediction variance over the design space.
- V-optimality (variance)
- A third criterion on prediction variance is V-optimality, which seeks to minimize the average prediction variance over a set of m specific points.
Now back to our example, because the asymptotic covariance matrix associated with the LSE of 

and G-optimality seeks to minimize 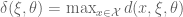
A central result in the theory of optimal design, the General Equivalence Theorem, asserts that the design 

the number of parameters.
Now the optimal design for an interference model, professor Wei Zheng will talk about, considers the following model in the block designs with neighbor effects:
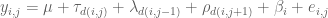
where 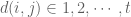

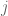

is the general mean;
is the direct effect of treatment
;
and
are respectively the left and right neighbor effects; that’s the interference effect of the treatment assigned to, respectively, the left and right neighbor plots
and
.
is the effect of the
is the random error,
.
We seed the optimal design among designs 



I am not going into the details of the derivation of the optimal design for the above interference model. I just sketch the outline here. First of all we can write down the information matrix for the direct treatment effect 


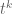

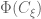
for any permutation matrix
;
is nondecreasing in the scalar
.
A measure 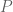
There has been a Machine Learning (ML) reading list of books in hacker news for a while, where Professor Michael I. Jordan recommend some books to start on ML for people who are going to devote many decades of their lives to the field, and who want to get to the research frontier fairly quickly. Recently he articulated the relationship between CS and Stats amazingly well in his recent reddit AMA, in which he also added some books that dig still further into foundational topics. I just list them here for people’s convenience and my own reference.
- Frequentist Statistics
- Casella, G. and Berger, R.L. (2001). “Statistical Inference” Duxbury Press.—Intermediate-level statistics book.
- Ferguson, T. (1996). “A Course in Large Sample Theory” Chapman & Hall/CRC.—For a slightly more advanced book that’s quite clear on mathematical techniques.
- Lehmann, E. (2004). “Elements of Large-Sample Theory” Springer.—About asymptotics which is a good starting place.
- Vaart, A.W. van der (1998). “Asymptotic Statistics” Cambridge.—A book that shows how many ideas in inference (M estimation, the bootstrap, semiparametrics, etc) repose on top of empirical process theory.
- Tsybakov, Alexandre B. (2008) “Introduction to Nonparametric Estimation” Springer.—Tools for obtaining lower bounds on estimators.
- B. Efron (2010) “Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction” Cambridge,.—A thought-provoking book.
- Bayesian Statistics
- Gelman, A. et al. (2003). “Bayesian Data Analysis” Chapman & Hall/CRC.—About Bayesian.
- Robert, C. and Casella, G. (2005). “Monte Carlo Statistical Methods” Springer.—about Bayesian computation.
- Probability Theory
- Grimmett, G. and Stirzaker, D. (2001). “Probability and Random Processes” Oxford.—Intermediate-level probability book.
- Pollard, D. (2001). “A User’s Guide to Measure Theoretic Probability” Cambridge.—More advanced level probability book.
- Durrett, R. (2005). “Probability: Theory and Examples” Duxbury.—Standard advanced probability book.
- Optimization
- Bertsimas, D. and Tsitsiklis, J. (1997). “Introduction to Linear Optimization” Athena.—A good starting book on linear optimization that will prepare you for convex optimization.
- Boyd, S. and Vandenberghe, L. (2004). “Convex Optimization” Cambridge.
- Y. Nesterov and Iu E. Nesterov (2003). “Introductory Lectures on Convex Optimization” Springer.—A start to understand lower bounds in optimization.
- Linear Algebra
- Golub, G., and Van Loan, C. (1996). “Matrix Computations” Johns Hopkins.—Getting a full understanding of algorithmic linear algebra is also important.
- Information Theory
- Cover, T. and Thomas, J. “Elements of Information Theory” Wiley.—Classic information theory.
- Functional Analysis
- Kreyszig, E. (1989). “Introductory Functional Analysis with Applications” Wiley.—Functional analysis is essentially linear algebra in infinite dimensions, and it’s necessary for kernel methods, for nonparametric Bayesian methods, and for various other topics.
Remarks from Professor Jordan: “not only do I think that you should eventually read all of these books (or some similar list that reflects your own view of foundations), but I think that you should read all of them three times—the first time you barely understand, the second time you start to get it, and the third time it all seems obvious.”
In mathematics, a general principle for studying an object is always from the study of the object itself to the study of the relationship between objects. In functional data analysis, the most important part for studying of the object itself, i.e. one functional data set, is functional principal component analysis (FPCA). And for the study of the relationship between two functional data sets, one popular way is various types of regression analysis. For this post, I only focus on the FPCA. The central idea of FPCA is dimension reduction by means of a spectral decomposition of the covariance operator, which yields functional principal components as coefficient vectors to represent the random curves in the sample.
First of all, let’s define what’s the FPCA. Suppose we observe functions 


is minimized. Once such a basis is found, we can replace each curve 




For FPCA, we usually adopt the so called “smooth-first-then-estimate” approach, namely,we first pre-process the discrete observations to get smoothed functional data by smoothing and then use the empirical estimators of the mean and covariance based on the smoothed functional data to conduct FPCA.
For the smoothing step, we have to consider individual by individual. For each realization, we can use basis expansion (Polynomial basis is unstable; Fourier basis is suitable for periodic functions; B-spline basis is flexible and useful), smoothing penalties (which lead to smoothing splines by the Smoothing Spline Theorem), as well as local polynomial smoothing:
- Basis expansion: by assuming one realization of the underlying true process
, where
are the basis functions, we have the estimation

- Smoothing penalties:
, where
is a measure for the roughness of functions.
- Local linear smoothing: assume at point
, then we have
estimated by the following

Once we have the smoothed functional data, denoted as 

And then we can have the empirical functional principal components as the eigenfunctions of the above sample covariance operator 


where
However, two common methods used in Statistics are described in Section 8.4 in the fundamental functional data analysis book written by Professors J. O. Ramsay and B. W. Silverman. One is the discretizing method and the other is the basis function method. For the discretizing method, essentially, we just discretize the smoothed functions 
- Basis expansion:
, and then
, where
and
;
- Covariance function:
;
- Eigenfunction expansion: assume the eigenfunction
;
- Problem Simplification: The above basis expansions lead to


where 



Note that the assumptions for the eigenfunctions to be orthonormal are equivalent to 


which is a traditional eigen problem for symmetric matrix 
Two special cases deserve particular attention. One is orthonormal basis which leads to 

Note that the empirical functional principal components are proved to be the eigenfunctions of the sample covariance operator. This fact connects the FPCA with the so called Karhunen-Lo

where 




So far, we only have discussed how to get the empirical functional principal components, i.e. eigenfunctions/orthonormal basis functions. But to represent the functional data, we have to get those coefficients, which are called FPC scores

Note that for the above estimation of the FPC scores via numerical integration, we first need the smoothed functional data
Degrees of freedom and information criteria are two fundamental concepts in statistical modeling, which are also taught in introductory statistics courses. But what are the exact abstract definitions for them which can be used to derive specific calculation formula in different situations.
I often use fit criteria like AIC and BIC to choose between models. I know that they try to balance good fit with parsimony, but beyond that I’m not sure what exactly they mean. What are they really doing? Which is better? What does it mean if they disagree? — Signed, Adrift on the IC’s
Intuitively, the degrees of freedom of a fitting procedure reflects the effective number of parameters used by the fitting procedure. Thus to most applied statisticians, a fitting procedure’s degrees of freedom is synonymous with its model complexity, or its capacity for overfitting to data. Is this really true? Regularization aims to improve prediction performance by trading an increase in training error for better agreement between training and prediction errors, which is often captured through decreased degrees of freedom. Is this always the case? When does more regularization imply fewer degrees of freedom?
For the above two questions, I think the most important thing is based on the following what-type question:
What are AIC and BIC? What is degrees of freedom?
Akaike’s Information Criterion (AIC) estimates the relative Kullback-Leibler (KL) distance of the likelihood function specified by a fitted candidate model, from the unknown true likelihood function that generated the data:

where 

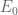



where 
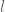



Schwarz’s Bayesian Information Criterion (BIC) is just comparing the posterior probability with the same prior and hence just comparing the likelihoods under different models:

which is just the Bayes factor. Schwarz showed that in many kinds of models 

which leads to the definition of BIC

In summary, AIC and BIC are both penalized-likelihood criteria. AIC is an estimate of a constant plus the relative distance between the unknown true likelihood function of the data and the fitted likelihood function of the model, so that a lower AIC means a model is considered to be closer to the truth. BIC is an estimate of a function of the posterior probability of a model being true, under a certain Bayesian setup, so that a lower BIC means that a model is considered to be more likely to be the true model. Both criteria are based on various assumptions and asymptotic approximations. Despite various subtle theoretical differences, their only difference in practice is the size of the penalty; BIC penalizes model complexity more heavily. The only way they should disagree is when AIC chooses a larger model than BIC. Thus, AIC always has a chance of choosing too big a model, regardless of n. BIC has very little chance of choosing too big a model if n is sufficient, but it has a larger chance than AIC, for any given n, of choosing too small a model.
The effective degrees of freedom for an arbitrary modelling approach is defined based on the concept of expected optimism:

where 






Why does this definition make sense? In fact, under some regularity conditions, Stein proved that

which can be regarded as a sensitivity measure of the fitted values to the observations.
In the linear model, we know that (Mallows) the relationship between the expected prediction error (EPE) and the residual sum of squares (RSS) follows

which leads to 
Here are some references on this topic:
-
Dziak, John J., et al. “Sensitivity and specificity of information criteria.” The Methodology Center and Department of Statistics, Penn State, The Pennsylvania State University (2012).
-
Janson, Lucas, Will Fithian, and Trevor Hastie. “Effective degrees of freedom: A flawed metaphor.” arXiv preprint arXiv:1312.7851 (2013).

Recent Comments